2024/11 Update
忙しくなくなると使わなくなる。
参考
chromeのDart Debug Extensionという拡張機能のインストール
VS codeのデバックでFlutter(web serverを選択する)
ブラウザが立ち上がる
Dartの主な特徴として、下記が挙げられます。
・オブジェクト指向型
・動的型付けと静的型付けの使用が可能
・JavaScriptやJavaに似ている
・操作性がシンプルで使用しやすい
・セキュリティ性能にも優れている
・大規模なアプリ開発に向いている
Dartは、JavaScriptの代替言語として開発されました。加えて、JavaやC#の影響を受けていることもあり、JavaScripttやJavaに類似しているのが特徴です。そのため、学習を進めるにあたって、すでにJavaScriptやJavaを理解している方は比較的楽にDartの知識を身につけられるでしょう。

2022年11月にOpenAIという企業がリリースしたChatGPTについて。
Pythonのプログラムの解説を試してみました。
h, w, sy, sx, n = map(int, input().split())
s = [list(input()) for _ in range(int(h))]
time_lr = [input().split() for _ in range(int(n))]
directions = ["N", "E", "S", "W"]
now_direction = 0
time_index = 0
s[sy][sx] = "*"
for t_now in range(100):
if time_index < n and str(t_now) == time_lr[time_index][0]:
d = time_lr[time_index][1]
time_index += 1
if d == "L":
now_direction = (3 + now_direction) % 4
else:
now_direction = (1 + now_direction) % 4
if directions[now_direction] == "N":
sy -= 1
elif directions[now_direction] == "E":
sx += 1
elif directions[now_direction] == "S":
sy += 1
elif directions[now_direction] == "W":
sx -= 1
if sx < 0 or sx >= int(w) or sy < 0 or sy >= int(h) or s[sy][sx] != ".":
break
else:
s[sy][sx] = "*"
for y in range(int(h)):
for x in range(int(w)):
print(s[y][x], end="")
print()このコードは、グリッド上を移動するロボットのシミュレーションの実装です。
入力は次のように読み取られ、保存されます。
h, w: それぞれグリッドの高さと幅
sy, sx: ロボットの開始 y および x 位置
n: ロボットの回転命令数
s: 文字の 2D リストとしてのグリッド表現
time_lr: 時間と回転方向 (L/R) のペアのリスト
シミュレーションは 100 時間単位で行われます。 各時間単位で、コードは現在の時刻が time_lr のいずれかの時刻と一致するかどうかを確認します。 その場合、ロボットの方向はそれに応じて更新されます。 次に、コードは現在の方向 (北、東、南、または西) に基づいてロボットの位置を更新します。 新しい位置が範囲外または空きスペースでない場合、シミュレーションは終了します。 新しい位置が有効な場合は、アスタリスクでマークされます。
最後に、グリッド表現が印刷されます。
十分な解析結果と言えるのではないでしょうか。
2023.1.30追記
ChatGPTのソース解析結果を渡して、実行可能なソースが作れるか
→
できず。デバッグをしない。入力と出力の結果の判定をしないので、プログラム開発には使えない。(いまのところ)
https://w3layouts.com/?s=Brand&product_cat=0&post_type=product
Webアプリの開発では、あるテーブルにステータスカラムを持たせるということはよくあります。
今回は、実際に業務で遭遇したBadなステータスカラムの設計を教材として、正しいステータスカラムの設計とは何かを考えていきたいと思います。
ステータスの定義
ステータスとは文字通り、対象の状態のことです。
開発では、操作対象(オブジェクト)のある状態に名前をつけたり値を割り振ったりします。
例えば、記事が公開中であるか、下書き状態であるかです。
ステータスをそのように区別しなければならない理由としては下記があります。
・当該ステータスにおいてのみ、実行させたい処理がある
・当該ステータスでは、実行させたくない処理がある
アンチパターンその1. ステータスを抽出する粒度がおかしい
仮にYahoo!ニュースのようなニュースを配信するメディアがあったとします。
このメディアでは、記者が書いた記事を運営事務局が検閲し、内容に問題がなければ掲載を開始するという業務フローになっています。
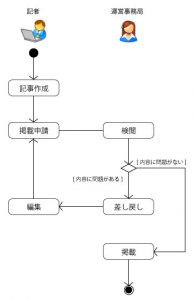
このケースで以下のようなデータ設計がされていたらどうでしょうか?
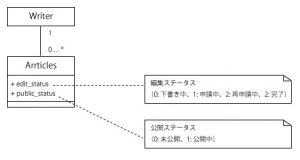
※ステータスにフィーチャーするため、ユーザIDなどの外部キーや記事本文など他のカラムについては記載していません。
まず、edit_statusというカラムについてです。
抽出されているステータスとして「申請中・再申請中」というものがありますが、両者は区別する必要はありません。
なぜなら、申請中というステータスは記者が事務局に「記事の内容を確認してね」という要請を出していますよという状態ですが、それが初回であろうが2回目の申請であろうが事務局が行う検閲という業務フローには影響がありません。
ステータスは抽出しようと思えば、いくらでも作れてしまいます。
例えば、対象を人間変えると「新婚・風邪・食あたり・食事中・休憩中」などなど。
こうなってしまうと際限がなくなってしまいますので、粒度が細かいものはまとめなければなりません。
ではどういった基準でまとめるのかというと、前述した「当該ステータスにおいてのみ、実行させたい処理がある」かどうかです。
例えば勤怠管理のシステムにおいて欠勤理由などを保存する場合「風邪・食あたり」では細かすぎます。「体調不良」というより大きな粒度にまとめてしまうといいでしょう。
制御に利用されないステータスは混乱を招くだけですのでなくすようにしましょう。
アンチパターンその2. ステータスが重複している
上記データ設計にはもう1点悪い箇所があります。
それはステータス保存するカラムが2つあることです。
まずこの実装でステータスを定義する目的は「記事を公開できる状態であるか区別する」もしくは「オペレーション(申請に対する検閲)が必要であるか区別する」ことです。
2つに分けられたステータスを比較したときに、これらを制御し得る値であるが複数存在しちゃっています。
表にしてみると一目瞭然です。
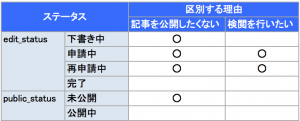
具体的に重複している箇所は以下の通りです。
・「下書き中」「未公開」はどちらかひとつあれば、記事を編集中であるかどうかは判断可能
・「完了」「公開中」はどちらかひとつあれば、記事を公開できる状態かどうかは判断可能
・※「申請中」・「再申請」は前述した通り
このケースだと、statusカラムは1つにまとめちゃって、値は「編集中・申請中・公開中」の3つにしてしまえばずっとシンプルになります。
以上、ステータスカラムの設計についてでした。
正規表現チェッカー
https://weblabo.oscasierra.net/tools/regex/
正規表現サンプル
https://www.megasoft.co.jp/mifes/seiki/index_s2.html
文字列結合
https://qiita.com/tmak_tsukamoto/items/e8d11b1fd5a479f03501
CASCADE
https://www.postgresql.jp/document/9.1/html/ddl-depend.html
TRUNCATE(削除)
https://www.postgresql.jp/document/9.1/html/sql-truncate.html
https://qiita.com/kazuho39/items/dc2fc540b64d15b727c2
PostgreSQLでSQLファイルの実行速度を計測する
https://qiita.com/SRsawaguchi/items/198c90ee6e402db9dfe7
windows-31jとshift_jisの違い
http://una.soragoto.net/topics/13.html
https://weblabo.oscasierra.net/shift_jis-windows31j/
utf8の判断の仕方
具体的には
/**
* ファイルはUTF-8ファイルかどうかを判定する
*
* @param file 読入ファイル
* @return 判定結果「true:UTF-8;false:以外」
*/
public static boolean encoding(File file) throws IOException {
InputStream in = new FileInputStream(file);
byte[] bt = new byte[3];
in.read(bt);
in.close();
if (bt[0] == -17 && bt[1] == -69 && bt[2] == -65) {
return true;
} else {
return false;
}
}
s-jisの文字コード
https://seiai.ed.jp/sys/text/java/shiftjis_table.html
タブ文字の削除
https://hydrocul.github.io/wiki/commands/tr.html
https://codenote.net/linux/3219.html
JavaのStringは文字数
https://www.javadrive.jp/start/string_class/index1.html
【linuxコマンド】nkfで文字コードを置換